본 포스트는 nomade.kr에서 나온 문제를 보고 직접 풀이한 포스트입니다.

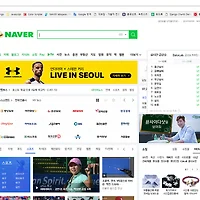
네이버에서 플래닛코스터를 검색했을때 목록을 출력해 보겠습니다.
플래닛 코스터는 제가 디자인감각과 창의성을 키우기위한 목적으로 시작한 롤러코스터게임입니다.
1. 살펴보기

검색했을때 주소를 살펴보면
https://search.naver.com/search.naver?sm=tab_hty.top&where=post&query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0&oquery=%ED%8C%8C%EC%9D%B4%EC%8D%AC+%EC%9E%98&ie=utf8&tqi=TUTyflpVuE8sssGoVu0ssssssUZ-259866
이렇게 됩니다.
기본 주소는 https://search.naver.com/search.naver 까지가 되겠고 그뒤에있는 ?부터가 제가 입력한 옵션과 검색 정보 파라미터 값들입니다.
저는 이 주소를 먼저 쪼개보겠습니다.
쪼갠 주소값
1 2 3 4 5 6 | sm=tab_hty.top& where=post& query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0& oquery=%ED%8C%8C%EC%9D%B4%EC%8D%AC+%EC%9E%98& ie=utf8& tqi=TUTyflpVuE8sssGoVu0ssssssUZ-259866 | cs |
&별로 묶여있기 때문에 &별로만 묶어보았습니다.
여기서 저희가 필요로 하는 것은 무엇일까요?
삭제하는 이유
1 2 3 4 5 6 | sm=tab_hty.top& 무엇인지 파악을 하지 못해서 일단 where=post& query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0& oquery=%ED%8C%8C%EC%9D%B4%EC%8D%AC+%EC%9E%98& 위에 쿼리가 있으므로 ie=utf8& 굳이 utf-8은 없어도 지장이 없을것 같으므로 tqi=TUTyflpVuE8sssGoVu0ssssssUZ-259866 무엇인지 모르겠으나 삭제 | cs |
1 2 3 | https://search.naver.com/search.naver? where=post& query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0& | cs |
https://search.naver.com/search.naver?where=post&query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0&
인 주소가 나왔습니다.
그럼 이 주소로 확인해 보겠습니다. 정말 이 주소로도 검색이 되는지요

검색이 아주 잘됩니다.
그렇다면 우리는 이 주소를 가지고 검색했을때 크롤링을 하여 정보를 가져오겠습니다.
2. 크롤링 시작

첫번째로 물음표 전까지인 주소를 요청 줘봤습니다.
''의 네이버 통합 검색결과입니다. 보이시나요?
이것은 빈값을 제가 검색버튼 눌렀을때와 똑같다는 뜻으로 해석할수 있죠.
그렇다면 어떻게 해야 검색한 대로 페이지가 나올까?
고민을 했습니다.
앞에서 url주소를 가지고 알아봤듯 주소뒷편에 파라미터값을 주면 되겠구나 생각을 했습니다.
주소에 파라미터값을 추가해서 서버에 요청하기

먼저 요청을 하기전에 url을 지정하고, params에 파라미터값들을 넣고 요청을 한 후에 응답을 text로 출력해 보았습니다.
어라? 플래닛코스터라고 잘 검색을 했네요?!
왜 query와 where가 파라미터로 갔는가?

해답은 주소에 있었네요.
제가 직접 검색을 할때 검색어는 query에, where=post로 보내야 검색이 되었기 때문에 이렇게 파라미터를 넣어 줬습니다.
html코드 살펴보기

제가 생각하기엔 sh_blog_title이 유일성이 있기때문에 이부분을 잘라서 해보겠습니다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import requests from bs4 import BeautifulSoup url = 'https://search.naver.com/search.naver' params = { 'query': '플래닛코스터', 'where': 'post', } response = requests.get(url, params=params) html = response.text #뷰티풀소프의 인자값 지정 soup = BeautifulSoup(html, 'html.parser') #쪼개기 title_list = soup.select('.sh_blog_title') for tag in title_list: print(tag.text) | cs |
확인

1페이지의 게시글들만 모두 출력되었네요.
이렇게 나온 이유는 blog검색할때 default값이 1페이지만 화면에 출력되기 때문에 그렇습니다.
모든페이지 정보를 가져와보기
https://search.naver.com/search.naver?where=post&sm=tab_pge&query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0&st=sim&date_option=0&date_from=&date_to=&dup_remove=1&post_blogurl=&post_blogurl_without=&srchby=all&nso=&ie=utf8&start=11
3페이지일때
https://search.naver.com/search.naver?where=post&sm=tab_pge&query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0&st=sim&date_option=0&date_from=&date_to=&dup_remove=1&post_blogurl=&post_blogurl_without=&srchby=all&nso=&ie=utf8&start=21
4페이지일때
https://search.naver.com/search.naver?where=post&sm=tab_pge&query=%ED%94%8C%EB%9E%98%EB%8B%9B%EC%BD%94%EC%8A%A4%ED%84%B0&st=sim&date_option=0&date_from=&date_to=&dup_remove=1&post_blogurl=&post_blogurl_without=&srchby=all&nso=&ie=utf8&start=31
페이지 넘버링에 대한 감이 오시나요?
맞습니다 맨 뒤에 &start=페이지번호 감이 딱 옵니다.
하지만 규칙성이 약간 특이하네요?
1페이지: 1
2페이지: 11
3페이지: 21
4페이지: 31
이런식입니다.
그럼 우리는 start값을 어떻게 줘야 할까요?
고민을 해봤습니다.
1, 11, 21, 31
어떤 공식일까요.
처음엔 1이였다가 갑자기 10이 추가됩니다. 그럼 이렇게 할수있겠죠
(page-1)*10+1 공식을 사용할 수 있습니다.
page가 1일때: 0*10+1 = 1
page가 2일때: 1*10+1 = 11
page가 3일때: 2*10+1 = 21
참쉽죠?
이제 이것을 코드로 옮기겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import requests from bs4 import BeautifulSoup url = 'https://search.naver.com/search.naver' for page in range(1, 1000): params = { 'query': '플래닛코스터', 'where': 'post', 'start': (page-1)*10+1, } response = requests.get(url, params=params) html = response.text #뷰티풀소프의 인자값 지정 soup = BeautifulSoup(html, 'html.parser') #쪼개기 title_list = soup.select('.sh_blog_title') for tag in title_list: print(tag.text) | cs |
일단 생각나는 반복문이 range였습니다.
1부터 1000까지 반복하는 문입니다.

밑줄친곳을 보시면 [*] 표시가 보이시나요? 코드를 실행한지 몇분이 지났는데 계속 긁어오고 있습니다
무조건 프로그램을 1000번돌리면 매우 비효율적일것입니다.
그래서 저는 어떻게하면 검색한 페이지가 있는만큼만 가져올까 고민을 했습니다.
검색한 만큼만 코드를 돌려보자!

이렇게 페이지가 비어있어도 계속 서버에 불필요한 요청을 보내고 있습니다. 코드역시 끝나지 않고 계속 돌고 있구요.
이것을 해결해 보겠습니다.
고민을 했습니다. (먼저 파이썬 자료구조에 대한 개념이 부족한 분들은 여기서 숙지하시면 됩니다.)
(아래 링크 클릭하시면 해당 내용의 정리글로 새창이 열립니다)
먼저 검색 결과를 list나 dict에 넣어서 마지막값들이 중복되면 실행을 멈추게 하면 되는데 dict vs list중 무엇을 선택하느냐죠.
dict을 사용하면 key값이 있기때문에 나중에 꺼내기 편할것 같고, Dict의 특성상 key값은 중복이 되지 않기 때문에 list보다 적합하다고 생각이 들어 dict를 사용해보도록 하겠습니다.
하지만 dict는 시퀀스 자료형이 아니죠.(순서가 없는)
그래서 우리는 dict형태이지만 순서가 있는 OrderedDict모듈을 사용해 보겠습니다.
또한, return값을 사용하고, 사용자가 원하는 검색을 직접 할 수 있도록 함수까지 만들어 보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | import requests from bs4 import BeautifulSoup from collections import OrderedDict #순서가 있는 OrderedDict 불러오기 def rednooby_cralwler(input_search): url = 'https://search.naver.com/search.naver' post_dict = OrderedDict()#OrderedDict를 사용하며, key에 url을 넣겠습니다. #url은 유일성이기 때문에! for page in range(1, 1000): params = { 'query': input_search, #검색어를 사용자에게 받아옵니다. 'where': 'post', 'start': (page-1)*10+1, } print(params) response = requests.get(url, params=params) html = response.text #뷰티풀소프의 인자값 지정 soup = BeautifulSoup(html, 'html.parser') #쪼개기 title_list = soup.select('.sh_blog_title') for tag in title_list: if tag['href'] in post_dict:#지금 저장할 링크(key)가 이미 post_dict에 있다면 return post_dict#리턴해서 끝내버린다. print(tag.text, tag['href']) post_dict[tag['href']] = tag.text return post_dict | cs |

print(params)로 확인해본 결과 더이상 검색결과가 나오지 않자 코드를 끝내고, OrderedDict값을 return하여 출력하는 부분입니다.
굳이 반복문을 1000번 돌려야할까?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | import requests from bs4 import BeautifulSoup from collections import OrderedDict from itertools import count #count 불러오기 def rednooby_cralwler(input_search): url = 'https://search.naver.com/search.naver' post_dict = OrderedDict() for page in count(1):#1부터 무한대로 시작(break or return이 나올때까지) params = { 'query': input_search, 'where': 'post', 'start': (page-1)*10+1, } print(params) response = requests.get(url, params=params) html = response.text #뷰티풀소프의 인자값 지정 soup = BeautifulSoup(html, 'html.parser') #쪼개기 title_list = soup.select('.sh_blog_title') for tag in title_list: if tag['href'] in post_dict: return post_dict#여기 오게되면 count는 종료됩니다. print(tag.text, tag['href']) post_dict[tag['href']] = tag.text return post_dict | cs |

크롤링 성공!!!
과연 몇개의 페이지를 가져왔을까요?

잘가져왔네요.
게시글은 딱 1000개만 가져왔습니다.
이게 정말 잘 가져온 것일까요?

검색결과는 1,640개인데 1000개까지만 검색이 되어있네요
그이유는 바로..

라네요.
사용자 임의대로 페이지범위 지정하기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | import requests from bs4 import BeautifulSoup from collections import OrderedDict from itertools import count def rednooby_cralwler(input_search, max_page):#사용자로부터 max_page 받아오기 url = 'https://search.naver.com/search.naver' post_dict = OrderedDict() for page in count(1): params = { 'query': input_search, 'where': 'post', 'start': (page-1)*10+1, } print(params) response = requests.get(url, params=params) html = response.text #뷰티풀소프의 인자값 지정 soup = BeautifulSoup(html, 'html.parser') #쪼개기 title_list = soup.select('.sh_blog_title') for tag in title_list: if max_page and (page > max_page):#max_page가 있고, page가 maxpage보다 클때 return post_dict#return으로 종료 if tag['href'] in post_dict: return post_dict print(tag.text, tag['href']) post_dict[tag['href']] = tag.text return post_dict | cs |

2페이지까지만 잘나오네요!
성공적으로 오늘의 크롤링도 완료했습니다!
본 게시글은 nomade.kr의 강의를 참고하였으며, 실제 강의 코드와는 다릅니다.
'파이썬 프로그래밍 > 파이썬 크롤링' 카테고리의 다른 글
| [Python] 네이버 실시간검색어 크롤링 실습 (3) | 2017.07.24 |
|---|---|
| [Python] 크롤링 예제. Lv3 자바스크립트 렌더링 크롤링 풀이 (1) | 2017.07.21 |
| [Python] 크롤링 예제. Lv2 Ajax 렌더링 크롤링 풀이 (0) | 2017.07.21 |
| [Python] 크롤링 예제. Lv1 단순 HTML 크롤링 풀이 (0) | 2017.07.21 |
| [Python] Pillow 이미지 붙이기 예제. 웹툰 전부 붙이기 (1) | 2017.07.20 |