본 게시글은 nomade.kr의 문제를 보고 풀이한 게시글입니다.
문제 주소
https://askdjango.github.io/lv2/
1. 페이지 탐색

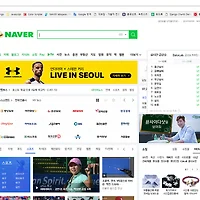
크롤링할 페이지 입니다. Lv1과 디자인은 똑같네요

[마우스 오른쪽 클릭] - [페이지 소스보기] 로 건질것이 없는지 찾아봅니다.
블록이 보이시나요? HTML단에서는 안나오네요

이럴땐 개발자 도구모드를 사용합니다. 이렇게 파트의 블록을 보며 따라가줍니다

벌써 찾아버렸네요. 여기 숨어있었습니다.
우리는 여기에 있는 이녀석을 크롤링해 보겠습니다.
먼저 이 페이지의 특징은 html에 보여지지 않고 숨어있기 때문에 이것을 꺼내서 확인해보겠습니다.

우측에 네트워크 탭을 선택하고 새로고침을 누르면 우측 하단처럼 시간초 별로 서버에서 응답하는 목록을 확인할 수 있습니다. 우리는 이 기능을 통해서 실습해볼겁니다.

무슨 서버가 무슨 파일들로 응답을 해줬는지 확인을 하던중 data.json파일에 목록들이 나오는 것을 발견하였습니다.
그럼 우린 이부분을 크롤링 하면 되겠죠?

헤더부분을 보시면 응답 URL을 저렇게 보내주는것을 확인할 수 있습니다.
이 파일을 받아와서 크롤링 해보겠습니다.
2. json파일 받아오기
1 2 3 4 5 6 7 8 9 10 11 12 13 | import requests import json #json header에 있는 json url 주소 json_url = 'https://askdjango.github.io/lv2/data.json' #받아온 json을 텍스트로 변환 json_string = requests.get(json_url).text #json모듈을 사용해서 로드 data_list = json.loads(json_string) print(data_list) | cs |
실행

json파일 불러와서 출력 성공!
그 다음으로 여기서 원하는 부분만 골라서 출력해 보겠습니다.
3. 원하는 부분 골라내기
1 2 3 4 5 6 7 8 9 | import requests import json json_url = 'https://askdjango.github.io/lv2/data.json' json_string = requests.get(json_url).text data_list = json.loads(json_string) for data in data_list: print(data['name'], data['url']) | cs |
8,9번째줄 추가입니다.
data_list에 데이터들이 차곡차곡 쌓이는것을 방금전 print문을 통해 확인하셨을 겁니다.
반복문을 사용해서 data_list(전체)만큼 반복문을 돌며 name, url을 한번씩 출력할 코드입니다.

성공했습니다.
1 2 3 | for data in data_list: print(data['name'], data['url']) print('{name} {url}'.format(**data)) | cs |
'파이썬 프로그래밍 > 파이썬 크롤링' 카테고리의 다른 글
| [Python] 네이버 실시간검색어 크롤링 실습 (3) | 2017.07.24 |
|---|---|
| [Python] 크롤링 예제. Lv3 자바스크립트 렌더링 크롤링 풀이 (1) | 2017.07.21 |
| [Python] 크롤링 예제. Lv1 단순 HTML 크롤링 풀이 (0) | 2017.07.21 |
| [Python] Pillow 이미지 붙이기 예제. 웹툰 전부 붙이기 (1) | 2017.07.20 |
| [Python] Pillow를 활용한 이미지 썸네일/다운로드 처리 크롤링 (0) | 2017.07.19 |